L’INA propose de passer cinq ans de médias au crible de l’IA
Intelligence Nationale Artificielle

L’INA a ouvert jeudi une plateforme dédiée à l’analyse des tendances médiatiques, sur un corpus de cinq ans d’archive. Sous-tendu par plusieurs outils d’IA, le projet permet par exemple d’explorer l’évolution des occurrences d’un mot donné sur les chaines d’information en continu. Le tout avec une méthodologie qui se veut transparente.
Les amateurs de linguistique ou de sociologie des médias vont pouvoir s’en donner à cœur joie. L’INA, l’organisme public chargé de valoriser les archives audiovisuelles et numériques, a mis en ligne sur data.ina.fr une plateforme de visualisation de données qui permet de naviguer de façon très intuitive dans un corpus de cinq ans d’émissions radio et TV diffusées entre 2019 et 2024. Dans le détail, il promet l’accès à 700 000 heures de programmes : des journaux télévisés, le flux des chaines d’information en continu et les matinales de radio.
Montrer la tendance de l’usage d’un nom ou d’un mot
À la différence de certains outils développés par l’INA en direction du monde universitaire, cette nouvelle plateforme se veut tournée vers le grand public. Il n’est donc pas question d’accéder directement aux jeux de données, mais plutôt de les explorer par l’intermédiaire d’entrées, qui font office de grille de lecture, pour analyser l’évolution du traitement médiatique au fil des cinq années couvertes par le corpus : nom de personnalité, mot clé, lieu géographique, ou répartition du temps de parole entre les femmes et les hommes.
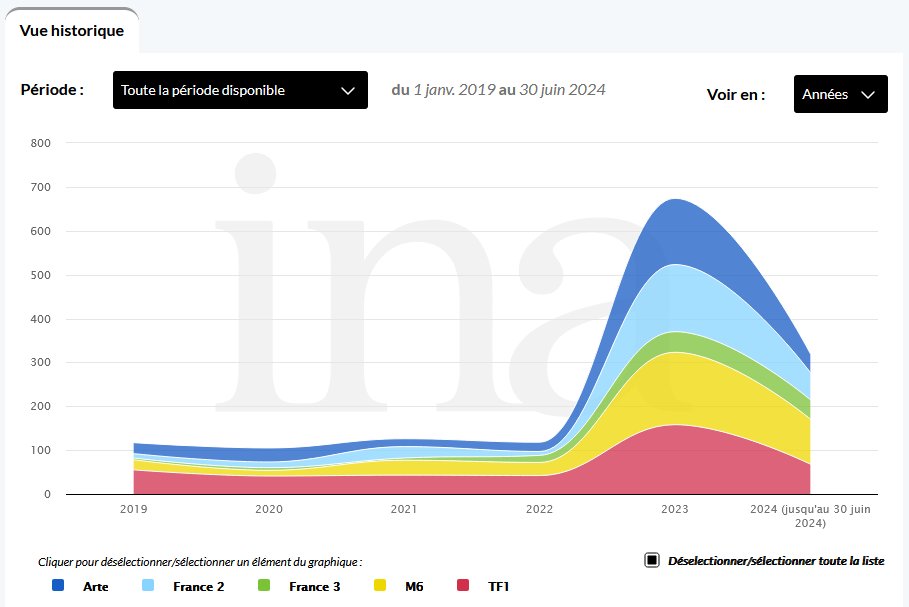
La plateforme permet ainsi de comparer très simplement la fréquence de mentions relatives à des personnalités politiques, en visualisant les différences de traitement d’une chaîne à l’autre. Elle propose aussi de visualiser l’ampleur de certains phénomènes médiatiques : ci-dessus, une recherche sur le terme « intelligence artificielle » illustre par exemple comment les chaînes de télévision se sont emparées du sujet suite à la sortie de ChatGPT.
D’autres requêtes livrent des résultats plus subtils. « Avec data.ina.fr, on peut comprendre des évolutions de société saisissantes, en réalisant que « metoo » n'a jamais été autant prononcée sur les chaînes infos françaises qu'au cours du premier semestre 2024 - ce qui en dit long sur la manière dont un seul message posté sur twitter en octobre 2017 peut produire des effets structurels sur les termes du débat public sept années plus tard », illustre par exemple sur LinkedIn Antoine Baylet, directeur éditorial de l’INA.
Un décompte réalisé par trois IA
Sur tous les écrans de sa plateforme, l’INA procède à des rappels méthodologiques, qui commencent par une mention systématique : l’exploration repose sur une transcription de la parole prononcée dans des archives audio ou vidéo réalisée de façon automatique.
L’institut de Bry-sur-Marne exploite pour ce faire trois outils d’intelligence artificielle, dont deux sont externes : Whisper, l’outil de transcription speech to text d’OpenAI, et TextRazor, une API d’extraction de mots clé d’origine britannique. L’INA y ajoute une troisième brique, développée en interne cette fois. Baptisée INASpeechSegmenter, elle calcule « la répartition des sons entre la parole des femmes, des hommes, le bruit, la musique et le silence dans un document audiovisuel », explique la FAQ du site.
Une procédure de contrôle basée sur des échantillons
Reste une dernière étape, et non des moindres pour que l’outil tienne sa promesse : contrôler sa fiabilité. Sur ce point, l’INA se veut là aussi transparente, avec un processus en quatre étapes détaillé dans sa FAQ, qui commence par une vérification de la complétude et de l’intégrité des sources. L’institut indique ne pas chercher à corriger les éventuelles aberrations de la reconnaissance automatique : les transcriptions fautives sont simplement écartées. La clé de lecture « Personnalités » (qui sera sans doute l’une des plus utilisées) a quant à elle fait l’objet d’un contrôle de pertinence sous forme de vérifications manuelles d’extraits sur l’équivalent de 1050 « top 20 ». Enfin, les équipes de l’INA expliquent avoir procédé à la transcription manuelle de 120 extraits de cinq minutes inscrits dans le corpus, pour vérifier l’efficacité du traitement automatisé. « On obtient ainsi un taux de confiance de 83% pour l’association de Whisper et TextRazor », indique l’INA, qui dispose par ailleurs de jeux de données spécifiques dédiés au monde de la recherche.
Faute de pouvoir résoudre toutes les confusions liées aux homonymies, la plateforme s’efforce par ailleurs d’alerter en cas de risque, par exemple quand le nom d’une personnalité est susceptible d’être confondu avec celui d’une marque ou d’un monument.

Commentaires (6)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 04/10/2024 à 15h27
- Guerre
- Immigration
- Gouvernement & népotisme
- Macron
- Hannouna
- Émissions de chansons (toujours les mêmes...)
- Beaucoup, beaucoup de publicités
- Foot
.......
- Nazis (au moins une soirée dédiée chaque semaine sur Arte)
Le 04/10/2024 à 16h28
Le 04/10/2024 à 16h26
Si ils prennent les 5 dernières années, peu de chance que cela fonctionne, tellement le "I" de IA risque de manquer :) L'algorithme d'apprentissage risque de se retrouver en PLS
Le 04/10/2024 à 16h29
Modifié le 04/10/2024 à 17h54
Avec Google Trends, on a peu ou prou les mêmes courbes avec vingt années d'historique.
Un exemple avec le terme "antisémitisme" (en bleu sur Trends) :
Pour "intelligence artificielle" :
Le 04/10/2024 à 18h13
Les autres sections par thématique sont assez intéressantes, notamment la différence des temps de parole homme/femmes selon les chaines. On constate une certaine régularité dans les résultats avec un écart pas spécialement élevé, même si déséquilibré en la faveur des hommes, sur la plupart des chaînes, sauf Canal+ où c'est plus en retrait pour les femmes.